VIA-SD: Verification via Intra-Model Routing for Speculative Decoding
Abstract
Speculative decoding (SD) addresses the high inference costs of large language models (LLMs) by having lightweight drafters generate candidates for large verifiers to validate in parallel. Existing draft-verify methods use binary decisions: accept or fully recompute. Yet we find that many rejected tokens can be verified correctly by a slim submodel derived from the full verifier via intra-model routing, instead of the full verifier. This motivates our slim-verifier to handle tokens requiring moderate verification resources, reducing expensive large-model calls. We propose Verification via Intra-Model Routing for Speculative Decoding (VIA-SD), a multi-tier framework using a routed slim-verifier. Draft tokens are processed hierarchically: direct acceptance for high-confidence cases, slim-verifier regeneration for medium-confidence cases, and full-model verification for uncertain cases. Across four typical tasks and multiple model families, VIA-SD consistently lowers rejection rates (0.1–0.22) and achieves 10–20% speedup over state-of-the-art SD methods. Compared to decoding without drafting, VIA-SD provides 2.5–3× acceleration while improving output quality. Moreover, VIA-SD is compatible with existing SD frameworks without modifying their training procedures. Our results suggest multi-tier SD as a general paradigm for scalable and efficient LLM inference.
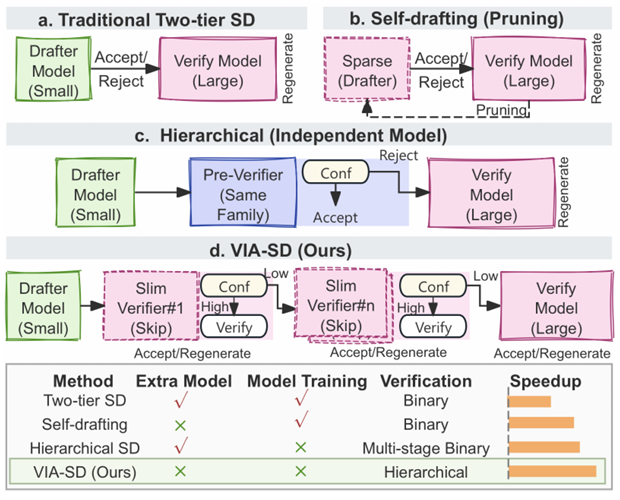
Figure 1. Comparison of speculative decoding (SD) paradigms. Our VIA-SD introduces a slim-verifier routed from the large model to enable hierarchical verification with low overhead.
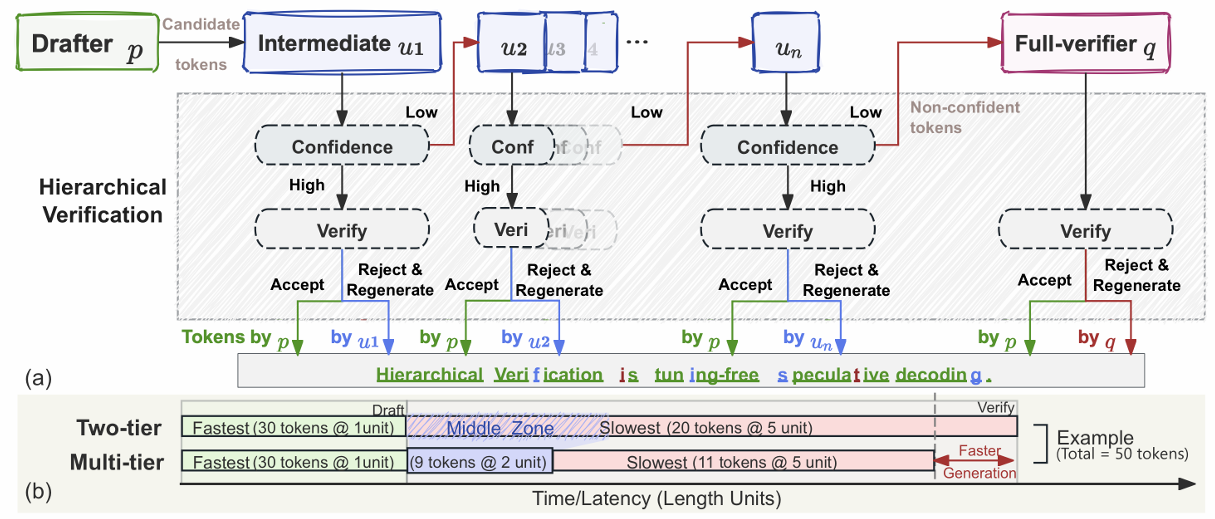
Figure 3. Illustration of our proposed VIA-SD pipeline. (a) Candidate tokens drafted by p are progressively verified by a hierarchy of intermediate verifiers, where high-confidence tokens are accepted early and only the remaining uncertain tokens are deferred to the full verifier q. (b) Latency comparison between two-tier and hierarchical multi-tier verification, showing reduced reliance on full-model decoding.
BibTeX
@inproceedings{xian2026viasd,
title = {VIA-SD: Verification via Intra-Model Routing for Speculative Decoding},
author = {Xian, Yuchen and He, Yang and Xu, Yunqiu and Yang, Yi},
booktitle = {Proceedings of the 43rd International Conference on Machine Learning},
year = {2026}
}